[研究1 (南)]
幼児の語彙獲得
幼児はどうやって言葉を覚えるのか?
幼児はりんごという「言葉」とりんごという「物体」を結びつけることで語彙獲得を行います。この語彙獲得について幼児は驚くべき能力を持っており、1歳でわずか10語だった語彙が2歳で300語、3歳でなんと1000語にも増えます。 このようなことがコンピュータでも実現できれば将来、自動的に言葉を獲得できるシステムが実現できると考え、研究を行っています。 しかし、この語彙獲得も含めた言語の獲得についてはまだまだ判明していない謎が多くあります。南研究室ではこの謎に対して、心理学的な分析を行いながら、それを工学に応用するため、分析的アプローチと機械学習的アプローチを用いて取り組んでいます。
分析的アプローチ
大量に収集した幼児の語彙獲得データから、幼児がどのように語彙を獲得しているのかを工学的な手法により分析を行います。
このような知見をもとに、人間の言語発達の過程を調べ、それを工学的に実現することを考えています。
機械学習的アプローチ
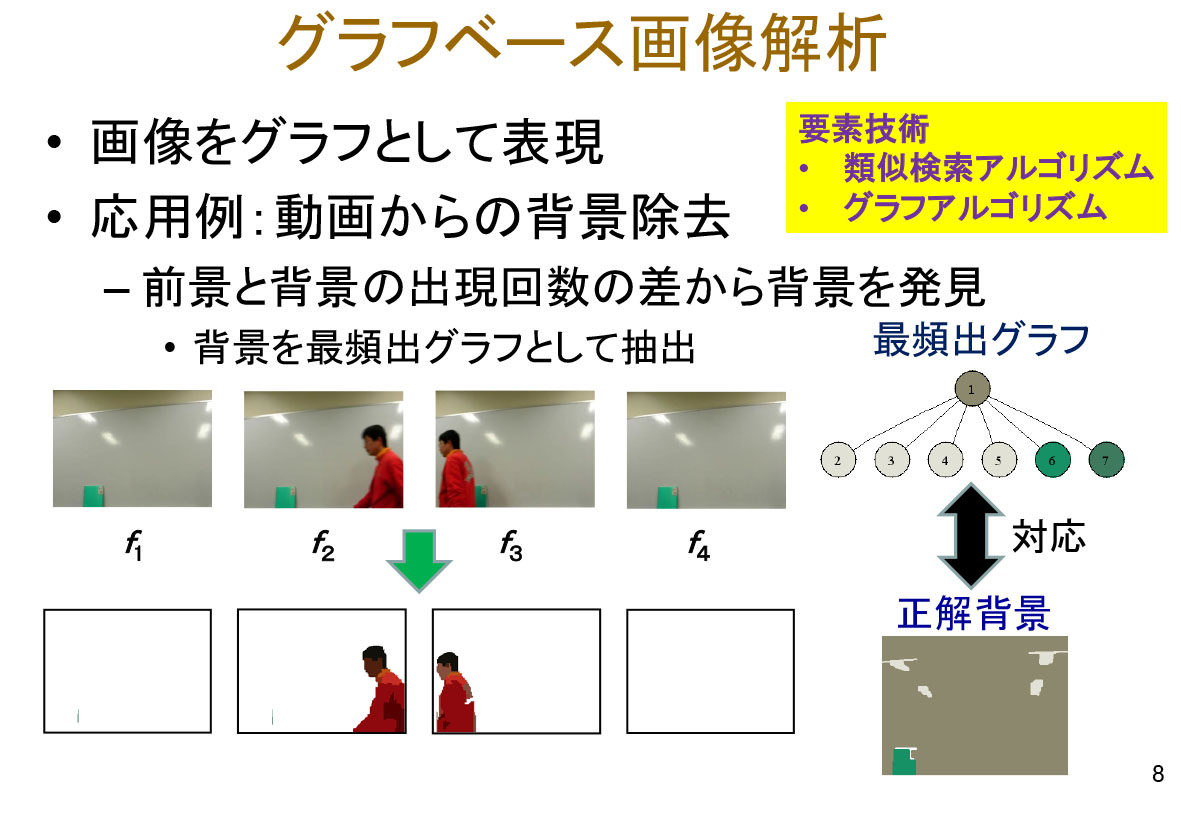
私たちが取り組んでいる手法の一つとして深層強化学習による幼児の語彙獲得機構のモデル化があります。これは親子間にある「共同注視」「意図の理解」に着目し、幼児は物体の特徴を獲得しながら語彙を獲得するというものです。(図参照) 現在、この研究により、幼児の語彙獲得において「暗黙的知識の獲得」などの仕組みが発生することが確かめられています。
認知症におけるBPSDの検出
東京都の「AIとIOTによる認知症高齢者問題の解決を目指す研究」に参画しています.ここでは,認知症高齢者,家族,介護者を支援する社会システムを
実現します.介護施設などからリアルタイムに集められた生体や行動に関するセンサーデータから暴言,暴力,徘徊(BPSDと呼ばれる)などの予測を行い,介護者や家族の負担を軽減する研究を行っています.
また,AMEDという医療系のプロジェクトにも参画し,音声認識による介護記録の自動作成などの研究も行っています.
論文執筆者支援
研究背景
近年、科学技術の発展と共に、分野を超えた研究も多数行われるようになりました。これに伴い、研究者が学術論文を執筆する際、比較すべき主要アプローチやベース手法を把握するために、関連する数多くの論文を調査することに大きな労力を払う必要があります。そこで、このような研究者の論文執筆を支援するために、論文自体を自然言語処理技術を用いて解析しています。
データセット作成
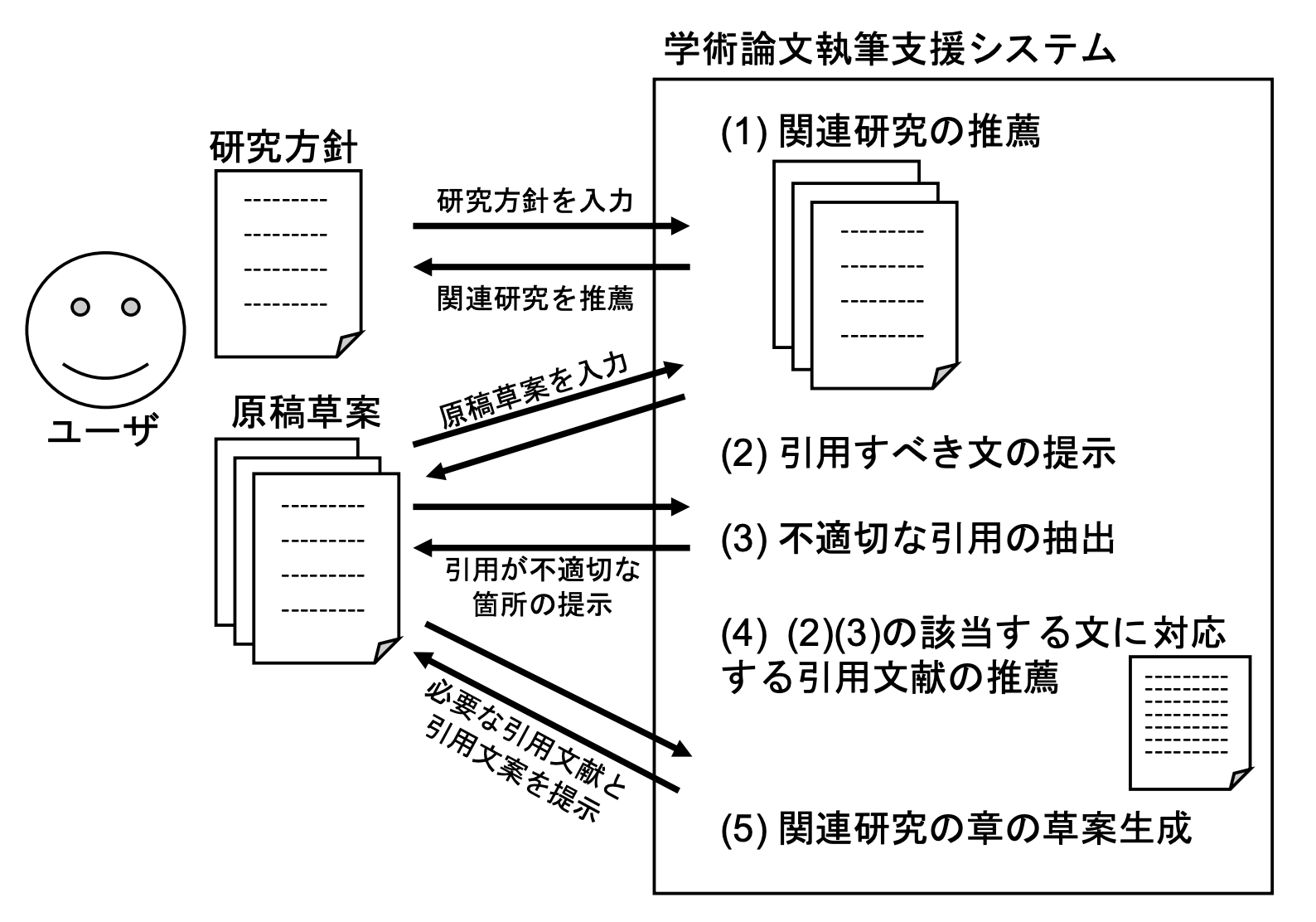
この研究では、実験に使用するデータを独自に作成しています。ベースとなる論文のPDFやTexのデータを収集し、それらのデータから論文のセクションや引用関係を抽出します。タスク内容
我々は論文執筆支援のためのタスクを定義しています。(下表)
論文中の文に引用が必要かどうか推定するタスクや、関連研究の章の自動生成をするタスクが例に挙げられます。
これらのタスクを高い精度で解くために、独自に作成したデータセットと自然言語処理に適したディープラーニング手法を使用しています。
[研究2 (古賀)]
- 類似検索アルゴリズム
- クラスタリング
- オンラインアルゴリズム
- インターネットアルゴリズム
複雑な情報システムを、経験や勘に基づいて制御するのではなく、システマティックに取り扱える対象にすることを目指して、基盤となるアルゴリズム理論の構築、およびそれを利用した応用システムの研究を行っています。アルゴリズムに関しては、ハッシュに代表される高速類似検索アルゴリズムの研究に力を入れています。また、与えられた情報をリアルタイム処理するオンラインアルゴリズムについても研究を進めています。応用システムとしては、グラフ・木構造を利用したメディア(イメージ、ビデオ)データからのパターン発見と認識、大規模データに対するクラスタリングアルゴリズムの開発、インターネットのトラフィック制御、といった研究テーマを取り扱っています。